RISC-V 乘法扩展如何为 RV32I 增加高效 32 位乘法运算
RISC-V 指令集架构 (ISA) 于 2010 年在伯克利问世。虽然 RISC 代表精简指令集计算机/内核,但制造商在使用 RISC ISA 时,总会忍不住在这里添加一条指令,在那里添加一种新寻址模式,填充操作码映射表,最后导致架构更像是 CISC(复杂指令集计算机),而不是 RISC。不过,伯克利的 RISC-V 开发人员非常严格地要求他们的内核是真正的 RISC。RV32I RISC-V ISA 在最初设计时仅有 47 条基础指令(这个数字对《星际迷航》的传统影迷有一种特殊的意义),11 年之后,指令数还是这么多。
之所以保持较少的基础指令数,其原本的理念是复杂 CISC 指令可以通过一系列的简单 RISC 指令实现。按照我的经验,这种做法是否能够提高代码效率和精简代码,要取决于应用。过去它确实发挥过这样的作用,以至于 Arm 将很多复杂指令添加到操作码映射表。
虽然更多指令能够帮助改进性能,但如果在 32 位内核上运行 32 位指令,然后您希望能够将一些 32 位指令压缩为 16 位指令以节省空间,那么情况会变得更加复杂。然而,若要增加 16 位指令,内核的操作码映射表必须具有更多空间来容纳这些压缩指令,而增加 CISC 指令会减少可用操作码数量。
在这种情况下,RISC-V 的优势真正得以发挥。Arm 后来增加了 Thumb2 压缩指令格式,通过添加单独的 16 位 ISA,将这些 16 位指令整合到现有的 ISA 中。但是,RISC-V ISA 从一开始设计时就提供了压缩指令的选项,因而仅有一个 ISA。这样可以使内核保持简单高效,也可以简化半导体设计和测试。
利用乘法指令增强 RISC-V RV32I ISA
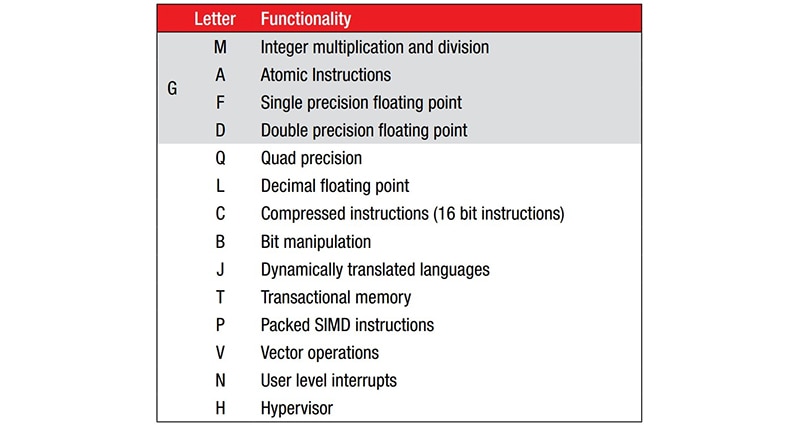
制造商可通过添加标准化指令扩展来扩展 47 条指令的 ISA(图 1)。由于基础 ISA 没有乘法或除法指令,因此 M 扩展提供了这种功能。例如,带有 M 扩展的 RV32I 会被命名为 RV32IM。
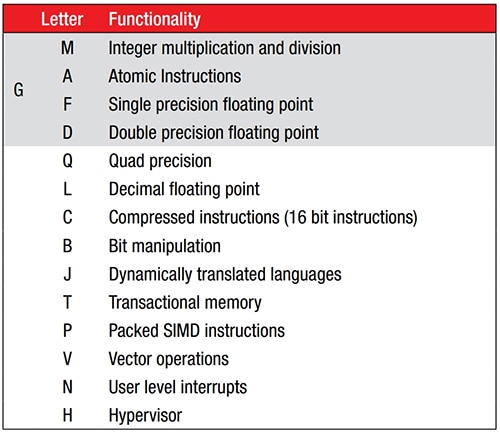 图 1:通过添加标准化指令扩展(用内核名称后的字母后缀表示),可扩展 47 条指令的 RISC-V 基础 ISA。(图片来源:RISC-V.org)
图 1:通过添加标准化指令扩展(用内核名称后的字母后缀表示),可扩展 47 条指令的 RISC-V 基础 ISA。(图片来源:RISC-V.org)
一个带有 M 扩展的内核示例是 SparkFun Electronics 的 RED-V Thing Plus,它采用开源 150 MHz Freedom E310 (FE310) 32 位 RISC-V 微控制器。该 FE310 内核被命名为 RV32IMAC。请参考图 1,除了基础整数计算 (I) 能力之外,它还支持整数乘法 (M)、原子指令 (A) 和压缩指令 (C)。
SparkFun 的 DEV-15799 RED-V(读作“红 5”)是一款 RISC-V 评估板(图 2),搭载 32 MB 的程序存储器 QSPI 闪存,带有 USB-C 连接器,可连接到主机以获取电源并进行编程和调试。另外还有一个连接器,可用于通过电池供电。
 图 2:SparkFun DEV-15799 评估板用于评估开源 150 MHz FE310 RV32IMAC RISC-V 内核。它通过 USB-C 接口连接到主机。(图片来源:SparkFun Electronics)
图 2:SparkFun DEV-15799 评估板用于评估开源 150 MHz FE310 RV32IMAC RISC-V 内核。它通过 USB-C 接口连接到主机。(图片来源:SparkFun Electronics)
M 扩展增加了有符号和无符号 32/32 除法指令 DIV 和 DIVU,以及有符号和无符号求余指令 REM 和 REMU。它还增加了四条乘法指令:
- MUL 执行 32 x 32 寄存器乘法,将 64 位结果的低 32 位存储在寄存器中。
- MULH 和 MULHU 分别执行有符号和无符号寄存器乘法,将 64 位结果的高 32 位存储在寄存器中。
- MULSHU 执行有符号 x 无符号寄存器乘法,将 64 位结果的高 32 位存储在寄存器中。
因此,对于 32 x 32 = 64 无符号乘法,推荐的代码序列为:
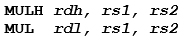
其中寄存器 rs1 和 rs2 分别是被乘数和乘数,寄存器 rdh 和 rdl 分别是高 32 位和低 32 位结果。
通过将 64 位乘法结果分为两个 32 位运算,ISA 便不需要添加复杂的 32 x 32 = 64 CISC 指令。这符合使用简单指令来执行 CISC 运算的 RISC 理念。
基础 RV32I ISA 中的大多数指令的执行仅需要 1 个指令时钟周期,但 RED-V FE310 中的这些乘法指令需要 5 个时钟周期。这样推算,上面的推荐代码序列需要 10 个时钟周期。虽然这在 150 MHz 频率下是可以接受的,但我见过一些功耗非常低、时钟速度非常慢的微控制器应用,中断在这些应用中至关重要,若在 5 MHz 的频率下执行 10 个时钟周期的乘法,关键中断是等不起这么长时间的。在此类情况下,我看到一些固件开发人员使用允许中断的复杂汇编语言子例程来执行乘法。
然而,FE310 内核能够接受连续指令,并通过宏融合,将这些指令内部融合为一条更快的指令。内核微架构可将两条指令融合为一条内部指令,这样其执行就不需要 10 个时钟周期。RISC-V 微架构自动对一些代码序列进行融合,例如 indexed loads、load-pair 和 store-pair 指令,从而显著加快执行速度。更大的好处是,由于 FE310 支持“C”扩展,可以融合两条兼容的 16 位压缩指令,因而在代码和执行速度方面都具备优势。
Arm 后来才在他们的架构中增加了宏融合,就像压缩指令那样,而 RISC-V 从一开始就在设计中提供宏融合。要真正了解代码压缩的优势,以及宏融合发生的时机,最好的方法是使用 SparkFun DEV-15799 等评估板来观察这些行为。您可在调试器中检测代码,了解 FE310 微架构如何提取和执行每条指令。这样您就能更好地了解汇编语言的行为,帮助您使用支持代码压缩和宏融合的 C 编译器来编写高效的代码。
结语
让人引以为傲是,RISC-V ISA 仅有 47 条基础指令,是真正的精简指令集。使用“M”乘法扩展等标准化扩展,可以增加乘法和除法指令,从而增强这种架构。宏融合是 RISC-V 架构固有的功能,可以加快兼容指令的代码执行速度,例如连续乘法指令,而“C”压缩扩展则可精简代码。相比其他架构,压缩指令和宏融合都能带来显著的性能优势。
关于此作者

Bill Giovino 是一名电子工程师,拥有美国雪城大学的电气工程学士学位,是先后从设计工程师、现场应用工程师跨界到技术营销部门的少数成功人士之一。
25 年来,Bill 一直喜欢在技术和非技术用户面前为包括 STMicroelectronics、Intel 和 Maxim Integrated 在内的许多公司推广新技术。在 STMicroelectronics 工作期间,Bill 作为领头人帮助该公司在微控制器领域取得了早期成功。在 Infineon,经过 Bill 精心策划,该公司的首个微控制器设计便在美国汽车领域大获全胜。作为 CPU Technologies 公司的营销顾问,Bill 帮助了许多公司,让其表现不佳的产品大获成功。
Bill 是物联网的早期尝试者,包括将第一个完整的 TCP/IP 协议栈植入微控制器。Bill 秉持“教育式销售”信条,在通过在线促销产品时强调清晰明了的书面沟通的重要性。他是广受欢迎的 LinkedIn 半导体市场营销群的群主,精通 B2E。

Have questions or comments? Continue the conversation on TechForum, Digi-Key's online community and technical resource.
Visit TechForum
此作者发布的其它博客