



目录
返回顶部
边缘计算
边缘 AI 和机器学习
机器学习训练方法
嵌入式 ML
ML 软件
TensorFlow
TensorFlow Lite
PyTorch 和 ExecuTorch
边缘 AI 和 ML 硬件
要求
NPU
TPU
Edge Impulse
用 AI 感知
带机器学习的视觉传感器
带有机器学习的运动传感器
边缘 AI
边缘计算正如其名,指的是在数据源附近进行计算,与云计算(在数据中心进行)相对应。 像智能家居助手(Alexa 或 Siri)这样的工具就内置了边缘 AI。 当您说出“Hey Alexa”时,边缘 AI 就会识别出这个短语并唤醒智能家居助手。



从零开始,玩转beaglebone AI64!AI边缘计算实战营 03
本期AI边缘计算特训实战营,就是基于这块Beaglebone AI开发板,为大家带来AI在自动驾驶,以及AIOT中的应用

边缘计算
随着对计算服务的需求日益增长,将算力从大型集中式数据中心转移出来可能看起来令人惊讶。 然而,在更靠近数据源的地方进行计算可以降低对隐私的担忧。 网络边缘以前是外设和终端的天下,现在我们可以在这里实现高级的处理能力。
许多实时活动正在推动对边缘计算的需求。 这些应用可能已经在您身边出现。
- 智能家居助手(如 Alexa、Google 和 Siri)使用“唤醒词”检测就是边缘计算的一种形式。 在这种情况下,必须要有边缘计算,因为设备需要快速响应并维护用户的隐私。
- 高级驾驶辅助系统 (ADAS) 聚焦驾驶员偏离车道时通知驾驶员等功能,不能等待云端的往返处理,否则会有网络延迟的风险。
- 患者监护(如葡萄糖监测仪)则需在患者身边操作。 可能只向患者的智能手机(或本地设备)发送数据,这样就减少了将受保护的健康数据暴露在互联网上的机会。
- 预测性维护模型会对工业电机的振动量进行异常检测,以检测电机何时会烧毁。 可能会触发警报(并在检测到异常时发送到云端),但其余时间软件都在边缘分析数据(这可减少网络拥堵)。
边缘计算和云计算有什么区别? 查看解答
云计算通常是指存在于数据中心(通常远离正在生成数据的处理地)的一组服务。 云计算工作负载在运行中央处理器 (CPU) 或图形处理器 (GPU) 的服务器上进行处理。
边缘计算指的是位于所生成数据附近的服务。 边缘计算工作负载通常在单片机或单板计算机 (SBC) 上处理。



利用非对称多核RISC-V SoC FPGA实现AI边缘计算,保姆级攻略在此!
RISC-V的发展持续火热,其低功耗、低成本、开源开放、模块化及可定制的特性吸引了各个技术厂商及设计工程师的关注,并引发了大家浓厚的兴趣。

使用 Efinix 已启用 Quantum 的 FPGA 实现低功耗、高性能的边缘计算
使用 Efinix 已启用 Quantum 的 FPGA,在 AI、ML 和图像处理的边缘计算实现中取得功耗、性能和面积增益。
边缘 AI 和机器学习
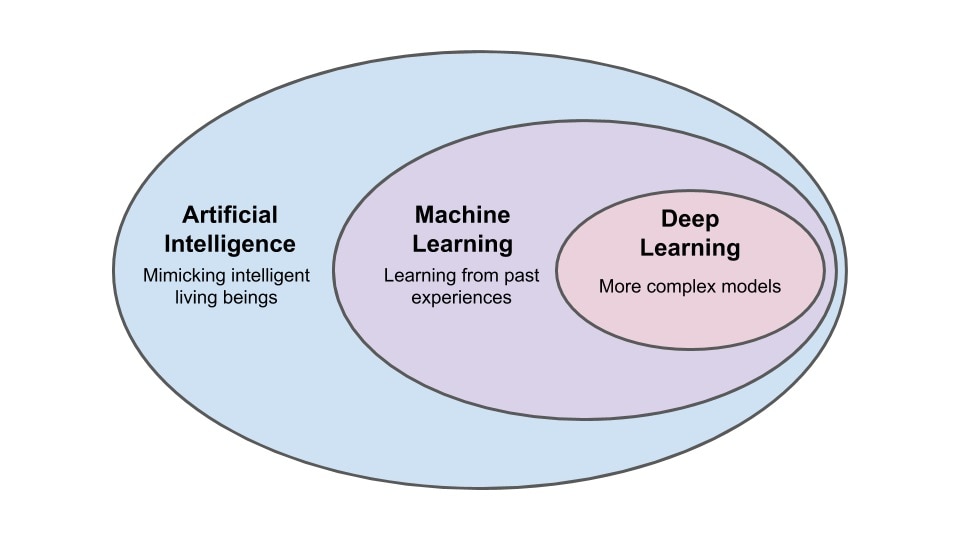
最广义的人工智能 (Artificial intelligence, AI)和机器学习 (Machine Learning, ML) 是指使用计算机算法和统计模型来提高任务执行效率,而不是发出直接明确的指令。这种能力能够实现自我改进和自适应,与需要明确定义每一个动作的传统编程不同,允许开发者不必定义每一个动作。这在从互联网内容推荐和语音识别到医疗科学和自动驾驶汽车等几乎所有领域都找到了新的用途。
现在,日常生活中越来越多的系统都有一定程度的人工智能交互,因此理解这个世界对于工程师和开发人员了解未来的用户交互方式至关重要。
人工智能 (AI) 是一个广泛的领域,尤其是机器学习 (ML),我们认为这在边缘技术领域应用的机会最多。 机器学习是一个基于统计算法进行模式匹配的过程。
神经网络的使用是机器学习中一种常见的训练方法。 下图标示了这种模型中的节点和权重。
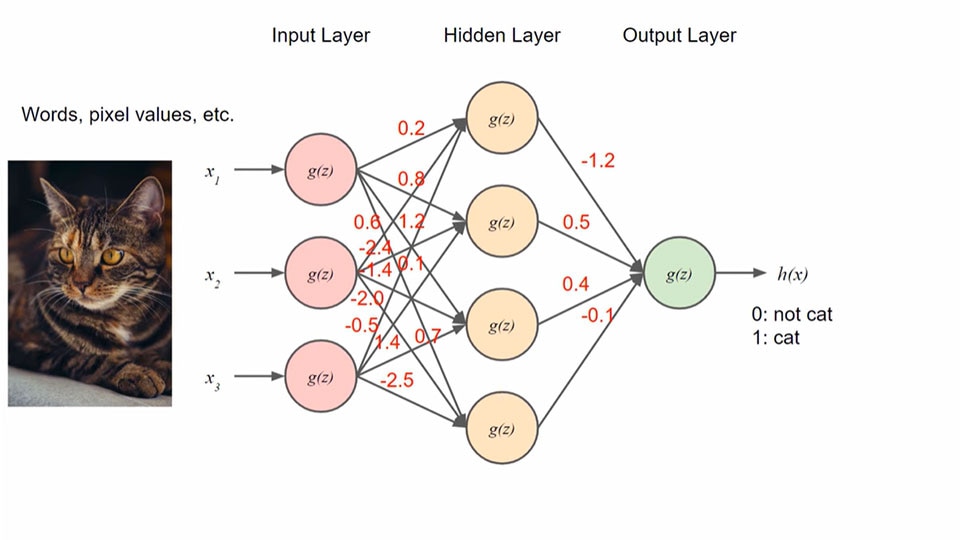 资料来源:
资料来源:深度学习是机器学习的一个专门类型,在神经网络中有多个隐藏的层。
 资料来源:
资料来源:什么是机器学习模型? 查看解答
机器学习模型是一种软件程序,它可以根据训练数据中发现的模式,识别输入数据并对其进行分类。 通过使用训练数据,ML 模型可以从数据中提取模式,然后使用这些模式来预测未来的结果并提炼更精确的模型。
机器学习训练方法
要获得有用的 ML 模型,必须对其进行训练。 有几种不同的学习方法可用于训练模型。
- 监督式 - 这是一种基于有标签和带标记的样本数据的训练,其中输出是一个已知的值,可以检查正确性,就像有一个导师在工作过程中纠正工作一样。 这种类型的训练通常用于分类工作或数据回归等应用中。 监督式训练非常有用,准确度也很高,但它在很大程度上依赖于带标记的数据集,可能无法处理新的输入。
- 无监督式 - 与有标签的训练数据和定义的输出不同,无监督式训练使用学习算法来研究、分析并从无标签的数据集中找到数据集群。 通常,无监督式训练用于需要研究大型数据集和发现数据点之间关系的应用中。
- 半监督式 - 混合了监督和非监督式训练。 训练数据集包含同时带标记和无标签的数据。 与其他方法相比,半监督式训练可以处理更广泛的输入数据,但它可能比监督式或无监督式训练更复杂,而且无标签数据的质量可能会影响最终模型的准确性。
- 从人类反馈中强化学习式 (Reinforcement Learning from Human Feedback, RLHF) - 这是一种需要使用明确定义的行动、性能指标和可以对结果评分及改进结果的训练类型。 通过定义规则集和可采取的行动,强化训练可以不断迭代,以评估实现目标条件的不同行动方案。
嵌入式 ML
嵌入式 ML 是机器学习的一个子集,专注于运行具有以下特性的模型:
- 低延迟(无需等待服务器或无需处理到达服务器的网络延迟)
- 低带宽(不通过网络返回高清数据)
- 低功耗(毫瓦级,而不是瓦级)
嵌入式 ML 模型可以部署在小型、低功耗设备(如单片机、FPGA 和 DSP)上,而非依赖大型数据处理硬件(如服务器或个人电脑)。
嵌入式 ML 应用的模型训练可以在服务器或计算机上进行。 这是一个输入所有数据并生成结果模型的过程。
嵌入式 ML 模型生成后,即可在嵌入式系统上运行。 嵌入式人工智能的常见应用包括识别和激活唤醒词、识别人或物,或根据传感器的数据流发现异常。
边缘 AI (或嵌入式 ML)有哪些优势? 查看解答
- 低延迟:无需等待远程服务器或处理网络延迟
- 低数据带宽:无需通过网络发送或返回大量高清数据
- 私密性:在边缘设备上做出决策,并对传感器输出进行预过滤,数据无需通过互联网传播
- 低功耗:嵌入式 ML 耗电是毫瓦级而非瓦级,非常适合电池供电型移动设备
- 数据占用空间小:嵌入式 ML 适合少量闪存,大约 几万字节量级
- 设备经济、成本低:嵌入式 ML 可在 32 位单片机上进行本地计算,整个系统的成本通常低于 50 美元。

TI Edge AI - AM6xA 处理器与深度学习加速器及其效率
TI 处理器与深度学习加速器 TI的AM6xA(如AM68Ax和AM69Ax)边缘AI处理器采用异构架构,带有用于深度学习计算的专用加速器。



使用 Soracom Beam 和 Amazon SageMaker 预测 M5Stack 的电力需求
今天,我想分享一个在科技界掀起波澜的令人兴奋的新整合。我说的是将Amazon SageMaker与Soracom Beam集成在一起,后者是一种数据传输服务,现在与AWS Signature V4兼容。

使用 Renesas RA8M1 MCU 快速地部署强大高效的 AI 和 ML 功能
使用 Renesas RA8M1 微控制器的 Arm Helium MVE SIMD 扩展,可快速高效地提供强大的 AI 和 ML。

Analog Devices的低功耗边缘AI处理器
介绍Analog Devices 的AI处理器MAX78000的基本特点,提供支持的内容,产品针对的IOT,工业及医疗等应用场景(市场),以及 Analog Devices AI MCU产品线规划。

ML 软件
TensorFlow
TensorFlow 是一个用于构建、训练和部署机器学习模型的免费开源软件库。 它最初于 2011 年由 Google 为 Google Brain 项目开发,2015 年向公众发布,2019 年发布了最新版本 TensorFlow 2.0。
TensorFlow 是最流行、使用最广泛的机器学习训练和深度神经网络推理框架。 许多开发人员通过其 Python API 库与 TensorFlow 进行交互,但 TensorFlow 也兼容 Java、JavaScript 和 C++ 编程语言。 第三方软件包增加了更多选择,几乎可以兼容 MATLAB、R、Haskell、Rust 等所有语言。
TensorFlow Lite
TensorFlow Lite 是 TensorFlow 的一个子集,专为小规模工作而设计。 这包括硬件有限和功率受限的设备,如嵌入式系统、移动设备和边缘计算设备。 开发人员可以在 TensorFlow 中训练、创建或修改现有的 ML 模型,然后使用 TensorFlow Lite 将其转换为更小、更高效的软件包,使之能够在移动设备上运行。
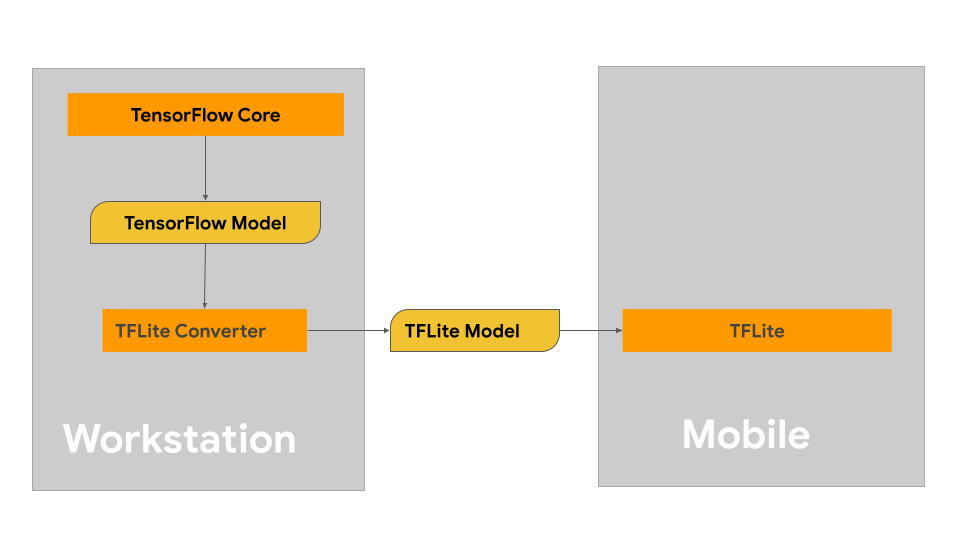 来源:
来源:然而,一旦部署到单片机平台上,设备上的 ML 模型通常就不会再有进一步的训练,因为这需要太多的算力和时间而无法在本地执行。 这意味着模型通常是在离线状态下完成训练的,没有新的数据源。 这种有限的方法非常适合执行单一任务的应用。 但需要对大量数据进行分类。
 来源:
来源:TensorFlow 和 TensorFlow lite 有什么区别? 查看解答
TensorFlow 需要较强大的计算硬件和完整的通用操作系统 (GPOS)。
TensorFlow Lite 针对在嵌入式系统、移动设备和边缘计算设备上运行 ML 模型进行了优化。
像运行 GPOS 的 Raspberry Pi 4 这样的单板计算机 (SBC) ,可以在适当大小的 SBC 上运行完整的 TensorFlow,但要注意功耗通常比 MCU 或 DSP 高得多,通常为 10 ~ 20 瓦。
一般来说,模型的训练将在 TensorFlow 上完成,但为了让模型在轻量级嵌入式系统上运行,会将其转换为在 TensorFlow Lite 上运行。
PyTorch 和 ExecuTorch
 来源:
来源:为了满足日益增长的在本地化硬件平台上运行 ML 模型的需求,PyTorch 开发了 ExecuTorch,这是一个完整的端到端软件工具,可在智能手机、可穿戴设备和嵌入式平台上运行机器学习模型。 从建模到转换和部署,ExecuTorch 都能使用与普通 PyTorch 相同的工具链和 SDK,而且还兼容各种 CPU、NPU 和 DSP 平台。
ExecuTorch 采用 PyTorch 2.0 技术,用户界面友好,支持多种设备,包括支持安卓系统的智能手机应用。
PyTorch Edge、ExecuTorch、PyTorch Mobile 是什么? 查看解答
PyTorch Edge 是在边缘运行 ML 模型的概念。 PyTorch Mobile 是实现这一概念的传统工具集,而 ExecuTorch 则是在边缘运行 PyTorch 模型的现代工具集。
PyTorch Mobile 是将 PyTorch 移植到移动设备(尤其是基于 iOS、Android 和 Linux 的设备)的早期尝试,但由于在应用启动时需要占用静态存储器,因此受到了限制。 而 ExecuTorch 有动态存储器,这意味着它只会在需要时才分配所需的存储器,这在存储器受限的环境中至关重要。
我能否在 PyTorch 上运行我的 TensorFlow 模型(或反之亦然)? 查看解答
虽然 TensorFlow 和 PyTorch 是类似的软件环境,但它们目前并不能直接交叉兼容。 由于每个系统使用不同的训练方法和模型文件输出,要把一个模型从一个生态系统用到另一个生态系统非常棘手。
幸运的是,有另一种方法可以让两者之间的转换变得简单。 ONNX(英文全称 Open Neural Network Exchange)是一个开源的 ML 软件系统,它有一个在 ML 生态系统之间转换训练模型文件的工具。
ONNX 作为 ML 生态系统之间的中间步骤,允许开发人员使用多种不同的 ML 训练方法,并跨越一系列方法进行模型优化。



边缘 AI 和 ML 硬件
TensorFlow Lite for Microcontrollers 是一个机器学习软件平台,专为单片机级应用而设计。 无需操作系统 C 或 C++ 库或动态内存的应用使 TensorFlow Lite for Microcontrollers 的体积更小,但功能却比标准编程选项强大得多。
为什么要在单片机上运行边缘 AI ? 查看解答
单片机小巧、灵活、低功耗、低成本,全球数十亿设备都在使用。 在不需要完整计算机系统的情况下,单片机具有优势。 单片机在本地决策和处理传入数据方面的能力,对 ML 领域具有特殊意义。 本地处理数据的另一个好处是可以保护终端用户的隐私。 例如,您可能想知道是否有人走近您家门口,又不想将门铃的视频数据保存在系统中。
要求
单片机 TensorFlow Lite 采用 C++17 编程语言开发,需要 32 位单片机平台才能运行。
TensorFlow for Microcontrollers 的软件内核操作可在 ARM Cortex M 平台上运行,存储器容量仅为 16 KB,也已移植到流行的 EPS32 平台上。 如果您喜欢使用合适的 Arduino 平台,甚至还可以为 TensorFlow Lite for Microcontrollers 框架开发 Arduino 软件库。
TensorFlow Lite for Microcontrollers 有哪些限制? 查看解答
TensorFlow Lite for Microcontrollers 是一个功能强大的机器学习平台,可以在最小的硬件要求下运行,但也存在一些限制,可能会使开发工作面临挑战:
- 官方仅支持少量设备,通常是高功率 32 位平台
- 与 TensorFlow Lite 一样,不支持单片机上训练。
- 支持一小部分基本 TensorFlow 操作。
- 存储器管理可能需要低级 C++ 应用编程接口 (API)。
其他嵌入式系统
在更强大的硬件系统上部署 ML 模型,只要可以运行嵌入式 Linux 或 SBC(如 Raspberry Pi 平台),TensorFlow lite 平台也就可以运行。
硬件加速器
在芯片层面,某些处理器增加了更多专用算术逻辑,以帮助机器学习和神经网络进行数学运算。
NPU
神经处理单元 (NPU) 是一种专用集成电路,旨在加速处理基于神经网络的机器学习和人工智能应用。
神经网络是基于人脑的结构,具有许多相互连接的层和称为神经元的节点,用于处理和传递信息。
TPU
张量处理单元 (TPU) 是 Google 于 2015 年开发的专用集成电路,旨在帮助处理基于神经网络的系统,但与 NPU 不同的是,它不是通过基于神经元的系统架构来完成的,而是通过快速处理矩阵乘法和卷积运算来完成的。
TPU 在处理数学矩阵运算方面进行了高度优化,能耗较低,非常适合训练使用此类运算的 ML 模型,如 TensorFlow 和 ExecuTorch。
第一代 TPU 硬件由于对电源和冷却要求较高,通常只用于数据中心应用。 但最新一代的 TPU 则专为基于边缘的应用而设计。
为什么 CPU 和 GPU 在边缘 AI 中使用的不多? 查看解答
传统的中央处理器 (CPU) 非常适合通用操作,但没有经过优化,无法高效处理神经网络的所有运算。 图形处理单元 (GPU) 在机器学习和人工智能应用中也非常有用,但由于能耗和所需硬件开销较大,所以在边缘应用中的使用受到了限制。
入门级产品

Arduino® Nano 33 BLE Sense Rev2
NINA-B306,nRF52840 带针座 Arduino Nano 33 BLE Sense Rev2 - ARM® Cortex®-M4F MCU 32-位 评估板 - 嵌入式
中级产品




高级产品


专家级产品


附加产品

如何将 Seeed 板添加到 Arduino IDE
Seeed 设计了许多可以使用 Arduino IDE 的开发板,包括以下: Seeeduino XIAO Seeeduino Wio Terminal Seeeduino Lotus Cortex-M0+ Seeeduino LoRaWAN /GPS Seeeduino Cortex M0 注意 上面提到的板是 AT SAMD21 微控制器系列。

从 InPlay IN100 BLE Beacon 传感器到 Arduino ESP32 BLE/WiFi 网桥
描述 该项目演示了一个概念验证,其中来自 InPlay IN100 BLE Beacon 的广播温度数据被 ESP32 上运行的 Arduino BLE 扫描仪应用程序接收。

用树莓派、PyPortal Titano和machinechat JEDI One设置和测试MQTT broker服务器
描述 该项目使用machinechat的JEDI One物联网数据管理软件在树莓派4上设置了一个物联网MQTT broker 服务器。


AI 视觉不同玩法,一起试试二哈识图(HuskyLens)和树莓派配合
这次,我们会运用二哈识图(HuskyLens)和树莓派配合,尝试一下目前比较火热的几个人工智能视觉识别方向,并把相应结果存储到数据库中。

为什么以及如何将 Efinix FPGA 用于 AI/ML 成像 — 第 1 部分:入门指南
借助 Efinix FPGA 和关联的开发板,设计人员可以快速开发和部署 AI/ML 成像应用。
Edge Impulse
Edge Impulse 是一个基于云的集成开发环境 (IDE),允许软件开发人员收集和导入真实世界的数据,构建、训练和测试 ML 模型,使之能够在边缘计算设备上高效运行。
 Edge Impulse 和 TensorFlow 机器学习软件的区别。 使用 Edge Impulse 时可以通过抽象让使用者不必了解模型开发过程,而 TensorFlow 的开发则要使用者更多地参与这个过程。
Edge Impulse 和 TensorFlow 机器学习软件的区别。 使用 Edge Impulse 时可以通过抽象让使用者不必了解模型开发过程,而 TensorFlow 的开发则要使用者更多地参与这个过程。
Edge Impulse 的优势
从音频(来自麦克风)到图像(来自相机)再到传感器数据(来自振动传感器),Edge Impulse 框架都能处理。 其他一些例子包括:
- 物体识别和图像检测(用于检测人等物体)
- 通过语音检测“唤醒词”(用于智能家居助手)
- 异常检测(用于预防性维护)
- 活动/模式识别(用于简化流程)
为什么要使用 Edge Impulse? 查看解答
Edge Impulse 可以减轻 ML 训练软件(目前主要是 TensorFlow)的工作量。 Edge Impulse 提供了一个基于 Web 的界面,可在此标记和上传数据以对模型进行训练。
Edge Impulse 专为从未使用过 ML 训练软件的新用户或非 ML 开发人员而设计,但由于它与 TensorFlow python 框架兼容,因此也完全可以扩展到专家级用户。 通过消除大部的边缘 AI 模型创建编码障碍,用户可以更多地将精力放在提供正确的数据/训练正确的模型上,而较少关注应包含哪些 Python 库来运行代码。
虽然为大多数开发人员和用户提供了免费版本,但每个项目可使用的项目数量和处理能力有限。 对于专业开发人员来说,Edge Impulse 有一个付费版,您可以联系 Edge Impulse 洽谈价格。

热爆的 ESP32 开发平台, 让你火速完成各种无线连接项目
FireBeetle ESP32-E或许会让你有些不一样的感受 - FireBeetle ESP32-E 是 DFRobot 在 FireBeetle ESP32 基础上精心打磨开发出的2代产品。

![]()

Nordic Semiconductor 的 Nordic Thingy:53 利用集成的运动、声音、光线和环境传感器来帮助构建概念验证和原型开发。

在此可以找到兼容 Edge Impulse 板卡的完整列表:
https://docs.edgeimpulse.com/docs/edge-ai-targets/fully-supported-development-boards
用 AI 感知
尽管运行机器学习模型需要嵌入式系统,但仍会有更多产品作为支持 AI 的电子元器件而不断推出。 这包括支持 AI 的传感器,也称为机器学习传感器。
机器学习传感器能做什么
虽然为大多数传感器添加机器学习模型并不会提高它们的应用效率,但有几种类型的传感器可以通过 ML 训练大大提高工作效率。
- 相机传感器,可以开发机器学习模型来跟踪画面中的物体和人物。
- IMU、加速计和运动传感器,用于检测活动轮廓。
带机器学习的视觉传感器
通过使用神经网络提供的计算算法,可以在物体和人员进入相机传感器视野时对其进行检测和跟踪。



AI 视觉不同玩法,一起试试二哈识图(HuskyLens)和树莓派配合
这次,我们会运用二哈识图(HuskyLens)和树莓派配合,尝试一下目前比较火热的几个人工智能视觉识别方向,并把相应结果存储到数据库中。





利用 Renesas 的 RZ/V2 系列 MPU 加速视觉识别系统设计
使用 Renesas 的 RX/V2 MPU,设计人员可以利用 DRP-AI 硬件加速器大幅加快视觉识别系统的速度。
AI 视觉传感器


带有机器学习的运动传感器
集成了机器学习平台的运动传感器能够在与传感器相同的封装内实时跟踪和处理数据,从而降低功耗和缩短处理时间。 大多数此类传感器都有一个基于计算逻辑的小型决策树,或者能够预定义过滤或触发阈值。 例如,当输入值达到这一水平时,就执行这个操作。 其他运动传感器则在封装中内置了完整的 DSP 单元,可以在不使用主 CPU 的情况下运行多种 ML 算法,从而节省了电能和时间。





使用 ATtiny1627 Curiosity Nano 简化运动探测
使用 Microchip ATtiny1627 Curiosity Nano 和 PIR 传感器快速探索并开始运动探测。

